多头注意力(Multi-Head Attention)
Attention
伪代码如上所示
Grouped Query Attentionppo
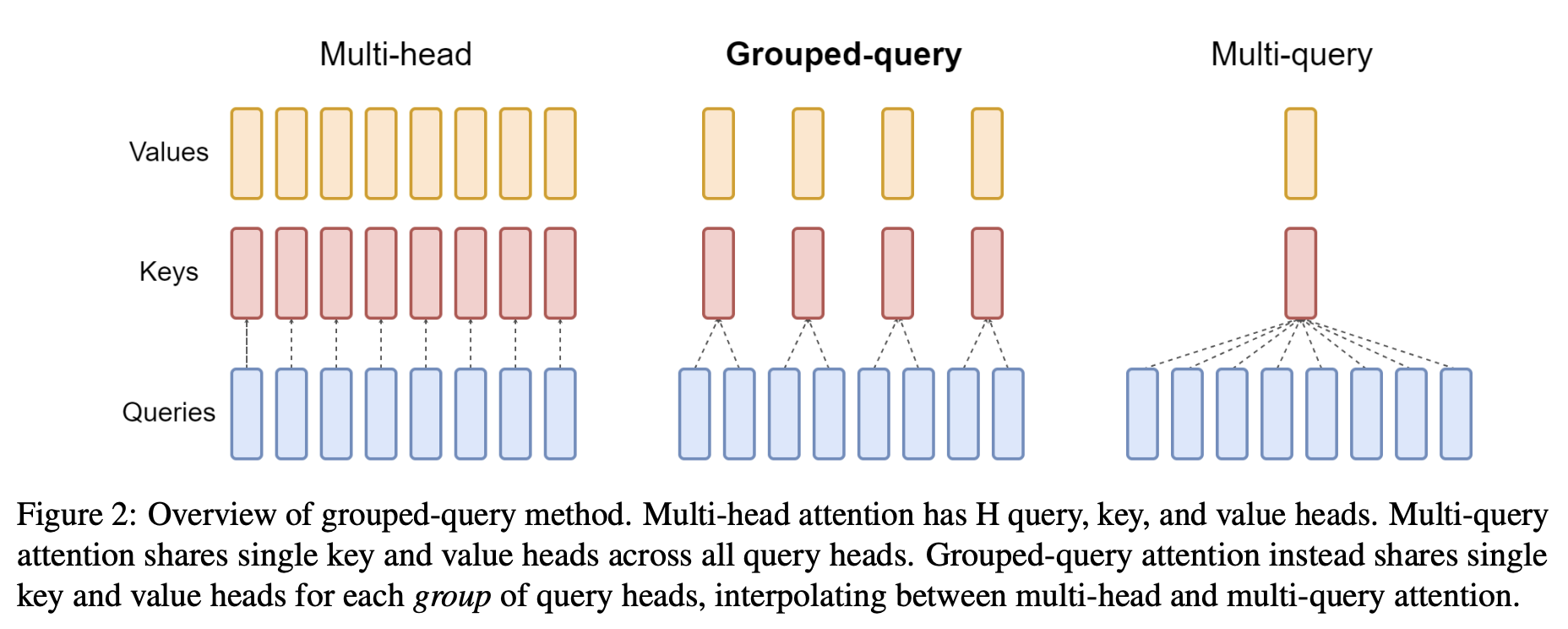
将 query 在 KV cache 当中保存了 G 份,这样现存就少很多了
query 是全量的 heads,可是 k-v 的 heads 就比较少了

计算逻辑

优点
减少了计算量
减少了 kv-cache 的容量,进而提升整个模型的吞吐
Multi-Lantent-Attention
伪代码如上所示
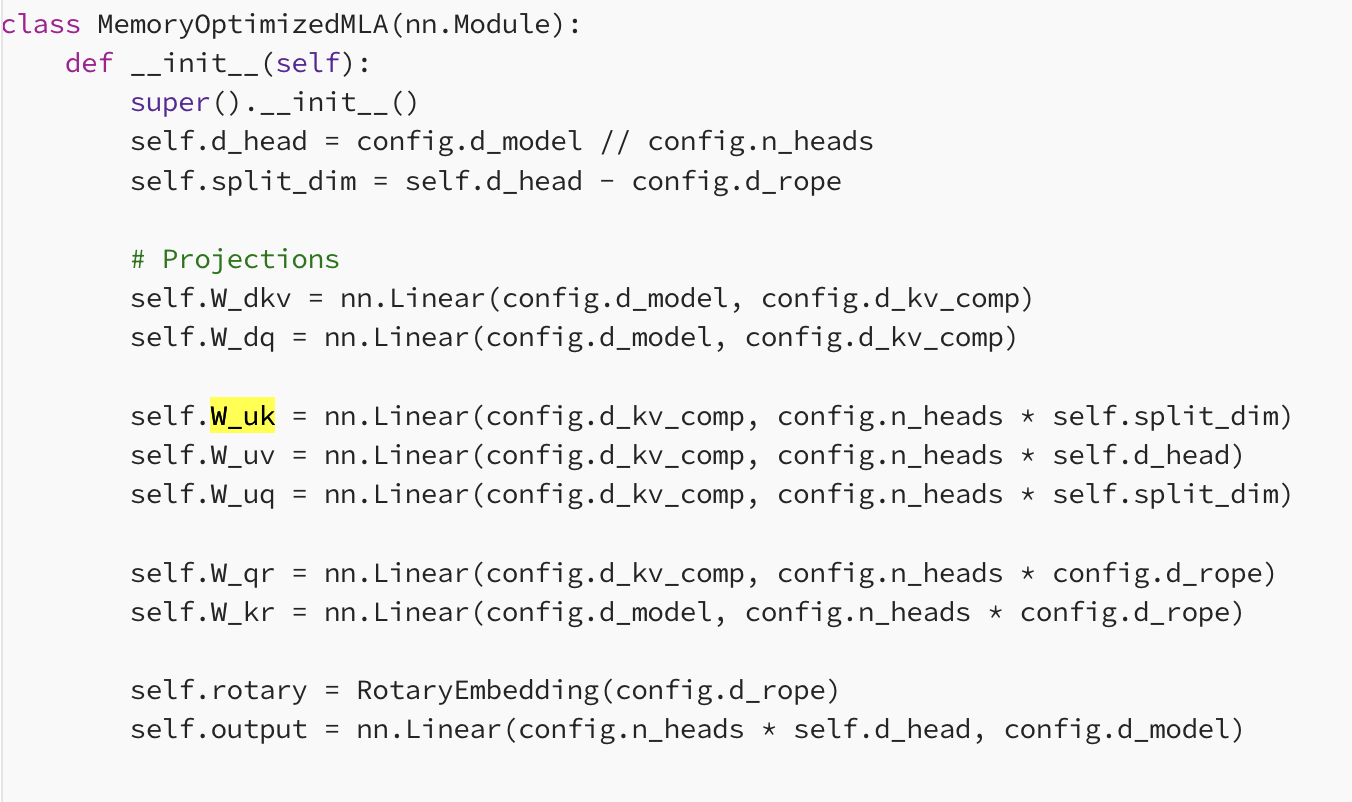
hidden_state = up(down(hidden_size))
稀疏与高效注意力(专章)
Ring Attention、NSA、滑动窗口、DeepSeek DSA、线性注意力等 长序列与稀疏注意力 内容已迁至专章,避免与原理篇重复维护:
- 2.3.6 稀疏注意力总览
- GQA / MLA 公式与图示见 2.3.4 注意力变体