学习率调度(Warmup、Cosine、WSD)
训练规模与学习率
Batch Size vs Learning Rate
openai 结论:更大的 batch_size 配备更大的 learning rate;更小的 batch_size 配备更小的 learning rate
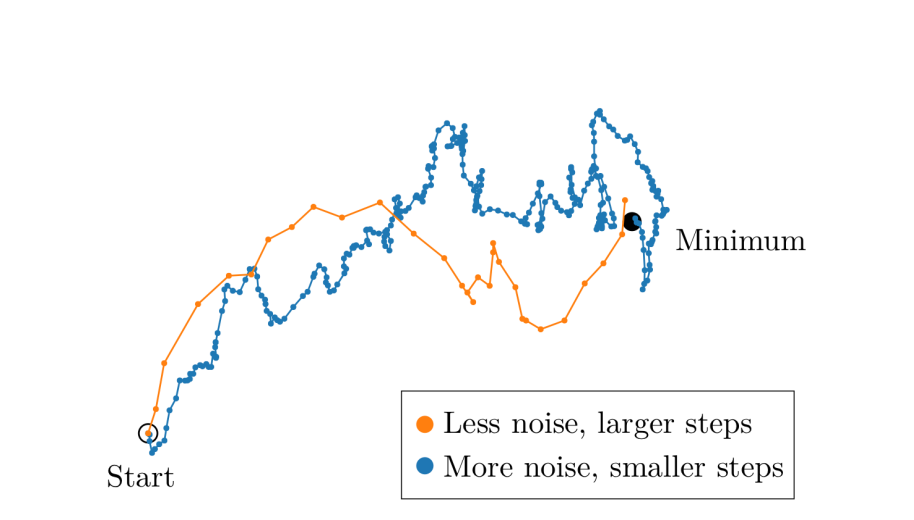
llya 曾在公开场合无数次强调,能开更大的 batch_size 就开更大的 batch_size,这样也能够避免资源的浪费。
解释
batch_size 更大 -> 训练样本数量更多 -> 可是对应的 gradient 更新梯度差不多,因为 loss 会做 average -> 为了保证能到达相同的终点,需要更大的 learning rate
不同 Size 的模型,Larger LLM 通常有 Larger Loss
参考链接:
https://gombru.github.io/2018/05/23/cross_entropy_loss/