Transformer
介绍
自然语言处理
自然语言处理(Natural Language Process)是研究如何让计算机理解、生成和处理人类自然语言的技术。自然语言包括各种人类日常交流的语言,如汉语、英语、日语等。NLP的目标是实现人类与计算机之间的有效沟通,使计算机能够理解和响应人类的语言输入。
传统NLP的核心任务包括但不限于文本分类、情感分析、命名实体识别、语义角色标注、语义解析、语言翻译、语音识别、语音合成等。这些任务涉及语言的各个层面,从词汇、语法到语义和语用,旨在使计算机能够全面理解和处理人类语言。
语言模型(Language Model, LM)

图片来源于:https://attri.ai/blog/introduction-to-large-language-models
自然语言处理(Natural Language Processing, NLP)中的语言模型(Language Model, LM)主要用于预测给定上下文中的下一个词或词序列的概率,故也可以认为它也是一个统计模型,以前被广泛应用于文本生成、语音识别、机器翻译等任务中。
大型语言模型(Large Language Model, LLM)
从字面上来看,大语言模型相比语言模型主要在大字上,也就是模型的参数量上要更大。这其实就带来了很多问题:
- 所需要的训练数据量更大,语料覆盖范围更广。
- 需要更多的算力来训练模型。
- 需要更多的机器来得以支撑整个大模型的训练。
- 如何在有限的计算资源下有效的进行模型,此时就需要多种模型训练策略。
这些问题在大语言模型时代都是需要解决的。
也正是因为模型更大,训练语料更多,大语言模型的各种能力就涌现出来了,可以说是大力出奇迹。
Transformer的基础理论
Transformer是2017年Google提出的一种基于注意力机制的序列到序列模型,它被广泛应用于自然语言处理任务中。Transformer在NLP领域中的地位和影响力不言而喻。
同时也是Bert、GPT、Llama等模型的基座方法,只是不同模型可能在一些细节上不一样,比如说位置编码、LayerNorm、FFN 等模块,整体上还是沿用 Transformer 的架构,接下来我来详细介绍一下Transformer中的每一个核心模块方法。
自注意力机制(Self-Attention)
自注意力机制是Transformer的核心,也是其最主要的创新点。自注意力机制可以看作是一种特殊的注意机制,它能够捕捉输入序列中不同位置的语义信息,并利用这些信息对输出序列进行编码。以下为自注意力机制的计算结构图:

其核心的计算公式为:
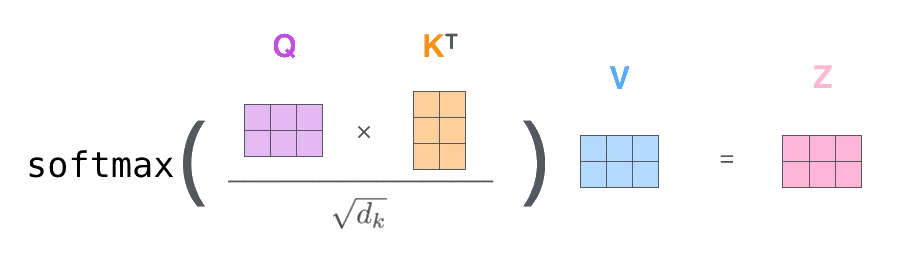
其中,、、分别代表查询(Query)、键(Key)、值(Value)矩阵,它们是通过输入序列与不同的权重矩阵相乘得到的。是键(Key)向量的维度,用于缩放点积结果,防止其过大导致softmax函数的梯度消失问题。函数用于将点积结果转换为概率分布,最后通过与值(Value)矩阵相乘,得到加权求和的输出。
Self-Attention 是双向编码机制,第 i 个token 可以看到当前输入文本中的所有token(i 前面的、i 后面的甚至i自己也是可以看得到的),其中手绘示意效果图如下所示:

大家也可以详细阅读一下优秀博客:
-
自注意力机制的基本原理
-
Query、Key、Value的计算过程
-
多头注意力机制(Multi-Head Attention��)的引入与优势
-
2.2 位置编码(Positional Encoding)
- 位置编码的必要性
- 正弦和余弦函数在位置编码中的应用
- 位置编码与词嵌入的结合方式
-
2.3 Transformer整体架构
- Encoder-Decoder结构概述
- Encoder的组成与工作原理
- Decoder的组成与工作原理
- 残差连接与层归一化在Transformer中的作用
第三章:Transformer的核心组件
-
3.1 输入层
- 文本分词与Tokenization
- Byte Pair Encoding(BPE)算法的应用
- 词嵌入(Word Embedding)的生成
-
3.2 自注意力层
- 自注意力层的详细工作流程
- 自注意力机制在处理长距离依赖上的优势
- 自注意力层的并行计算能力
-
3.3 前馈神经网络层(Feed Forward Neural Network Layer)
- 前馈神经网络层的作用与功能
- 非线性变换对模型性能的提升
- 前馈神经网络层与自注意力层的结合方式
第四章:Transformer的变种与扩展
-
4.1 基于Transformer的预训练语言模型(Pretrained Language Model, PLM)
- GPT系列模型介绍
- BERT模型及其特点
- 其他基于Transformer的预训练模型概览
-
4.2 Transformer在特定任务中的应用
- 机器翻译
- 文本生成
- 文本分类与情感分析
- 对话系统
-
4.3 Transformer的优化与改进
- 模型参数的压缩与剪枝
- 训练效率的提升方法
- 跨语言与多模态处理能力的扩展
第五章:Transformer的实际应用案例
-
5.1 在搜索引擎中的应用
- 基于Transformer的语义搜索技术
- 搜索结果的相关性与准确性提升
-
5.2 在语音识别中的应用
- Transformer在语音识别模型中的构建
- 识别准确率的提升与实时性优化
-
5.3 在推荐系统中的应用
- 基于Transformer的用户兴趣建模
- 个性化推荐算法的改进
第六章:未来展望与挑战
-
6.1 Transformer技术的未来发展趋势
- 更高效的模型架构与训练方法
- 更广泛的应�用场景拓展
-
6.2 面临的挑战与问题
- 计算资源消耗与模型可解释性
- 数据隐私与安全保护
- 多语言与跨文化的处理能力提升
第七章:结论
- 7.1 总结Transformer在LLM中的核心作用
- 7.2 强调Transformer对NLP领域的重要意义
- 7.3 展望未来NLP与AI领域的发展前景
这个大纲涵盖了Transformer在LLM中的基础理论、核心组件、变种与扩展、实际应用案例以及未来展望与挑战等多个方面,力求全面且详细地介绍Transformer在LLM中的重要作用与影响。