Transformer在2017年被提出时,作为一种序列转换工具将一个序列转换为另一个符号序列,最流行的例子是翻译,比如从英语到德语。它还被修改为执行顺序完成-给定一个启动提示,以相同的脉络和风格进行。它们已迅速成为自然语言处理领域研究和产品开发不可或缺的工具。
在此序列文章当中,我将从底层矩阵运算和梯度回传等细节讨论,甚至会把公式和代码对照着来讲解,此外还会介绍Transformer中常见的应用,当下流行不同预训练模型的差异化对比等。
Transformer 整体结构
为了让大家整体性的了解Transformer,我们先来看看模型结构图:
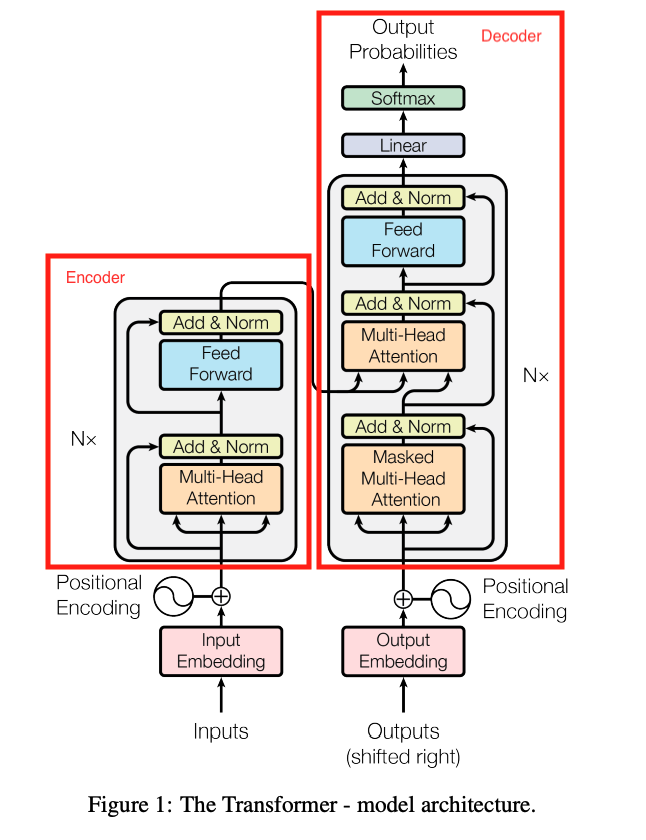
- 从模型组成部分上来看,主要是Embedding、Multi-Head Attentiony、FeedForward以及常见的Norm、Linear等组成部分。
- 从结构上看,可分为Encoder和Decoder模型
- 从模型类型上来看,可分为Encoder-only、Decoder-Only以及Encoder-Decoder等模型。
以上每一个模块可讲的内容都比较多,接下来我将尽可能的细化知识点,用通俗易懂的描述来介绍Transformer。
模型组成
从整体上来看,模型主要分为:输入、Encoder、Decoder、输出以及最终概率输出五个部分组成。
- 输入是指Encoder的输入,主要分为:Token Embedding、Position Embedding、Token Type Embedding。
- Encoder和Decoder在模型结构上一致,都是由多成TransformerLayer组成
- 而TransformerLayer又是由MultiHead Attention + 残差网络组成
- MultiHead Attention又是由 SelfAttention组成
- Decoder在输入上与Encoder不太一样,后者的QKV保持一致,所以是SelfAttention、前者Q来自于Encoder,KV来自于Decoder的输入
- 最终概率输出是在模型做预训练时才会使用到数值
模型结构
从结构上来看,主要分为Encoder和Decoder,前者主要是编码原始序列,比如汉语文本,后者编码目标序列,比如英语文本,以此可对两个序列进行文本翻译,实现一个序列转另外一个序列的功能。
顾名思义,Encoder主要是做语义编码的作用,可对文本语义做深度编码,比如Bert;Decoder主要是做解码作用,可解码成目标文本序列、语音甚至是图像都是可以的。
模型类型
在Transformer-Based模型上来看,可将模型分为三种类型:Encoder-Only、Decoder-Only以及Encoder-Decoder模型。
- Encoder Only
Encoder模型是BiDirectional、通常基于SelfAttention构建,且只能够编码语义,然后用于下游任务,比如:自然语言理解,文本分类,目标词预测,问答预测,文本情感分析,序列标注等等,而此类任务对于抽取某一个领域的信息十分在行,一般通过fine-tune之后能够达到很好的效果。
代表模型有: BERT、RoBERTa、ALBERT。
- Decoder only
Decoder模型是uni-directional,也就是单向的,为自回归模型,
代表模型有:T5, AlphaCode, Switch, ST-MoE, RETRO
- Encoder-Decoder
什么时候该使用Encoder-Decoder模型?做序列到序列的任务时,文本摘要,机器翻译等等;Encoder和Decoder之间的权重并没有共享;输入的分布和输出的分布不属于与同一个类别,如文本和图像的分布。
代表模型有:Dec-only: GPT-{1,2,3}, {🐭, 🐹}, PaLM
计算逻辑流程
源码解析
输入输出