Prompt已然成为新的模型训练方式,方法日新月异,所以全面
介绍
三要素
- Prompt Template
- Answer Search
- Answer Mapping
Prompt Template
主要负责将input转化成Prompt输入,通常带有[MASK]占位符,这样使用MLM模型即可获取此处的token类别分布。
Prompt Engineering vs Answer Engineering
- Prompt Engineering 主要负责Prompt 函数, 在Paddle-Prompt当中对应Template概念。
- Answer Engineering 主要负责答案搜索和答案映射两个任务,在Paddle-Prompt当中对应Verbalizer概念。
Answer Engineering
非受限空间
非受限空间所得答案即为最终答案,并不存在一个答案空间映射的过程,其中代表工作就是LAMA。
LAMA是特地用来测试语言模型所蕴含知识多少的数据集,这个数据集的每个数据,都包含了一个占位符,每个占位符只需要用一个token去填充,填充得到的结果就是最终的答案。例如对于三元组(实体头部,关系,实体尾部)构造得到的完型填空格式只会把实体尾部用占位符替换掉,然后去预测占位符位置的token,如果等于实体尾部,就说明模型具备这条知识,反之就说明模型不具备这个事实。每个占位符只能填充一个token,这里可以填充的token候选等于全词表,填充的答案就是最终的输出。
受限空间
此方法需要一个将答案空间映射到目标输出的过程,应用于文本分类、命名实体识别等任务中,
训练方法
参数更新方法
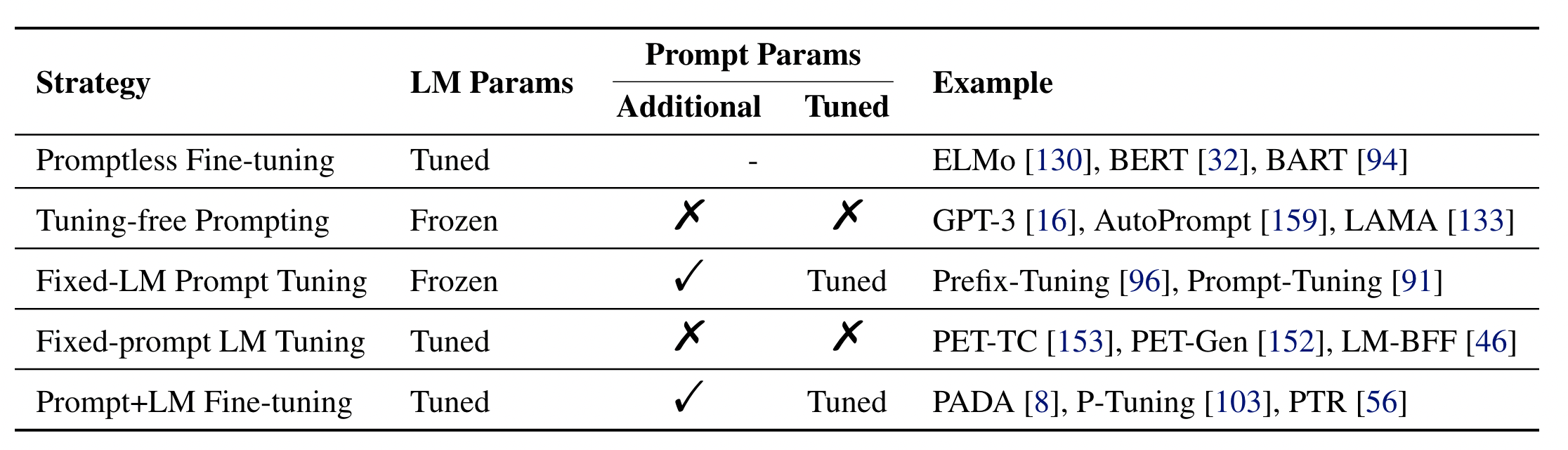
Promptless Fine-Tune
非Prompt训练方法,可认为常规的fine-tuning等训练方法。
Tuning-free Prompt
基于非受限空间构建的模型,能够直接获得最终答案分布,并不需要有一个答案映射的过程。
Fixed-LM Prompt Tuning
此类方法构建的模型当中,包含两类参数:LM和Prompt的参数,前者保持不变,后者可以tuning。经典方法是:Prefix-Tuning和WARP方法。
优点:
- 能够利用LM的先验知识
- 能够应用于few-shot的场景
- 效果通常要比Tuning-free Prompt方法要好
缺点:
- 并不适用于zero-shot的场景
- 在少样本领域有效,可是数据量太大的情况下,能力也是有限的。
- 需要进行seed prompt或者prompt engineering过程
- 训练之后的prompt并不具备一定的可解释性
Fixed-Prompt LM Tuning
此方法与Fixed-LM Prompt Tuning相反,Prompt的参数固定,LM的参数可以来训练。经典方法有:PET、LM-BFF等方法。
此外,也是有将Prompt Engineering取消掉的工作,直接构建:[X] [Z],中间并没有任何token,然后也是可以去得比较好的效果。
优点:
- 针对于few-shot场景下效果比较好
缺点:
- 也是需要一定的Prompt Engineering和Answer Engineering。
- LMs 在一个下游任务上的效果比较好,可并在另外一个任务上有可能并不会太好。
Prompt+LM Tuning
此方法中,LM和Prompt的参数都能够参与训练,此方法与传统的fine-tuning方法有些类似。代表方法有:PADA、P-Tuning等方法。
优点:
- 此方法能够适用于大规模数据。
缺点:
- 在小数据上很容易过拟合。
应用任务
Prompt可针对不同任务构造不同的prompt从而,