Cross Attention是用来处理两个不同Sequence时的SelfAttention变体。
介绍
属于Transformer常见Attention机制,用于合并两个不同的sequence embedding。而这两个sequence便是:Query、Key/Value。
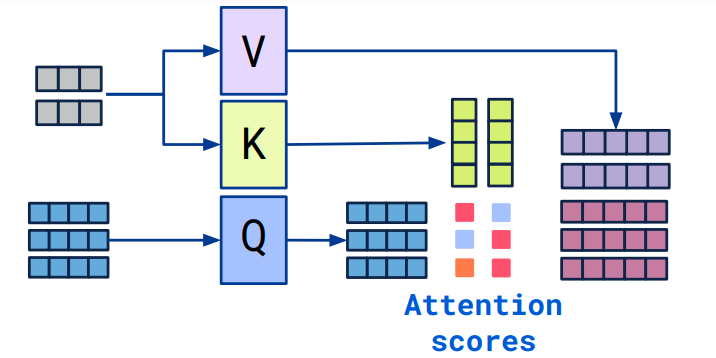
CrossAttention和SelfAttention的计算过程一致,区别在于输入的差别,通过上图可以看出,两个embedding的sequence length 和embedding_dim都不一样,故具备更好的扩展性,能够融合两个不同的维度向量,进行信息的计算交互。
而SelfAttention的输入仅为一个。
应用
其实基于CrossAttention的相关应用研究非常多,特别是处理不同数据来源的时候会有很好的效果。
比如:
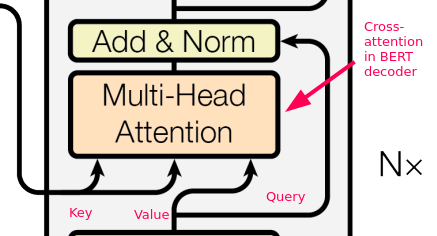
- Bert Decoder中有采用Cross Attention的机制。
- 在三种不同Embedding中的信息交互过程
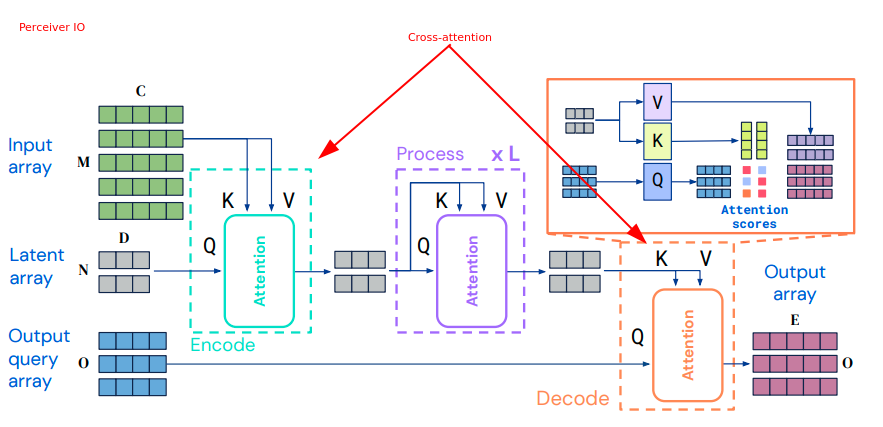
从上图可以看出,总共有三种数据来源,采用了Cross Attention和Self Attention的结合来建模。