作为NLP领域里程碑式的作品,对于其深刻的理解是很多后续学习工作的基础,更是面试找工作的利器。
介绍

Bert (Bidirectional Encoder Representations from Transformers) 是由谷歌AI NLP团队提出:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,是第一个无监督双向语言模型,一经发表就刷新了各大榜单,被定义为里程碑式的模型,让NLP达到了新的高度。
Bert是一个基于海量无结构化文本进行深度双向语义建模的预训练模型,通过Mask Language Model和Next Sentence Prediction两种训练任务,学习到文本中丰富的先验知识。实践证明,这些通用先验知识能够应用于各种下游任务,并取得SOTA效果,即使是在low-resource下也能够取得良好的效果。
解决了什么问题
模型参数数量这么大,必然需要海量的训练语料。从哪里收集这些海量的训练语料?《A Neural Probabilistic Language Model》这篇论文说,每一篇文章,天生是训练语料。难道不需要人工标注吗?回答,不需要。
为什么这么强
原因有三:
- 双向建模
- 使用MLM和NSP两种训练技巧
- 能够学习到Context-Heavy的Representation
用一句话来说就是:使用MLM和NSP两种训练技巧,基于双向建模能够学习到丰富上下文Representation。
整体结构
基于Transformer构建模型,bert-base模型当中参数为:L=12, H=768, A=12,参数数量为110M;Bert-Large模型中参数为:L=24, H=1024, A=16,参数数量为:340M。
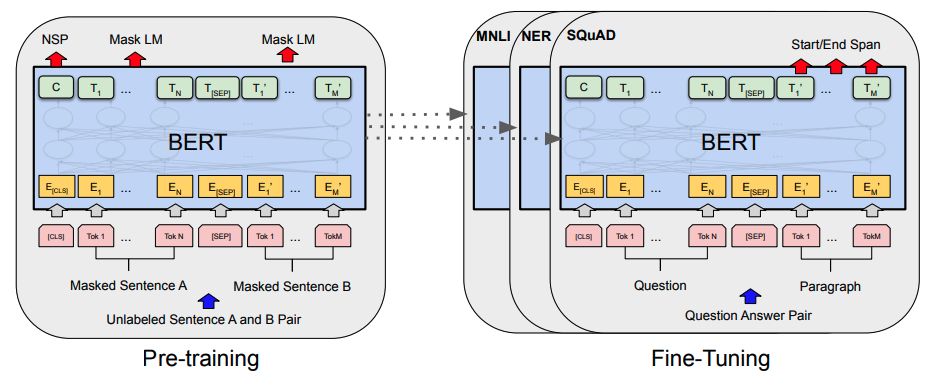
Bert其实是分为Encoder和Decoder两个部分,如果只是为了了解Bert是如何工作的,那只需要了解Encoder部分即可。
是由12层的双向Transformer构成,能够进行不同层面的特征抽取,那为了深入到Bert中的细节,那接下来将要介绍一下Bert的细节。
Transformer
Transformer是一个基于Attension机制的NLP基础组件,出自于《Attention is All you need》,OpenAI GPT和BERT都是基于Transformer。
下面我将以数据的流向为线索,来介绍模型中的细节。
问题定义
最初Transformer被用来解决翻译的问题,那此时就要求其具备:
- 能够步骤输入文本中词与词之间的关系
- 能够将以上关系映射到输出文本中
此时就需要一个Encoder和Decoder来处理这两个问题,结构如下:
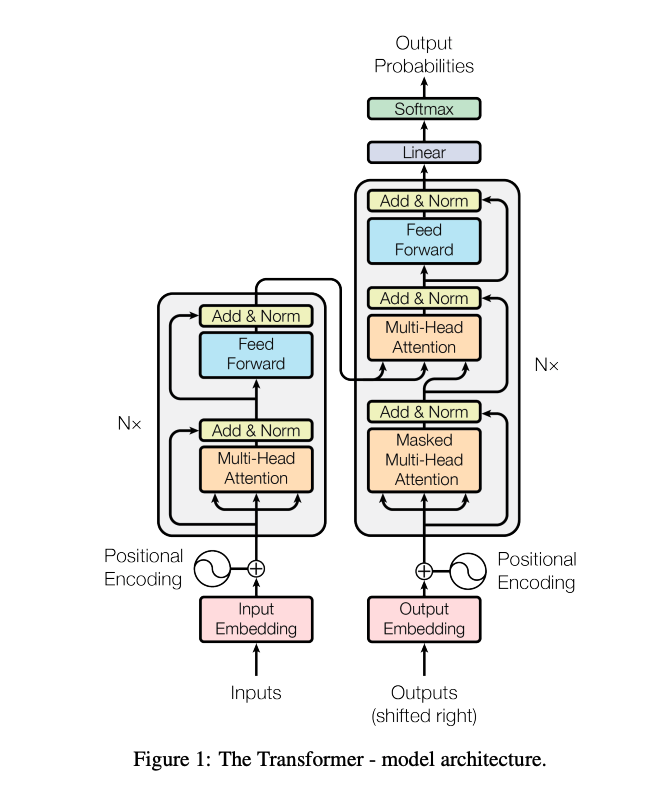
数据的流向
简化后的结构图如下所示:
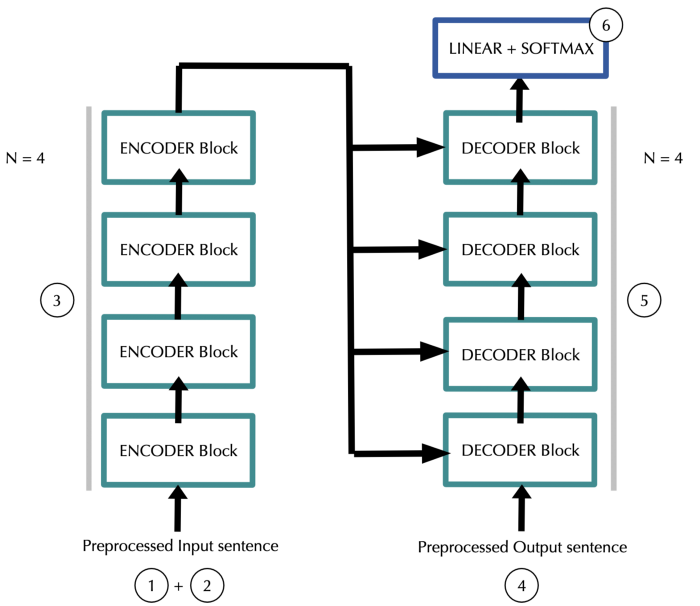
左边Encoder的输入为input sentence,右边Decoder的输入为target sentence,这两者用来做相关相似度计算。
- 在原始论文中,N为6.
- input sentence每一个单词为token,所以一个输入文本可编码为:
input_length*embedding_dim - 添加位置信息(positional information),维度大小同上:
input_length*embedding_dim - 数据经过N个Encoder之后的输出为:
input_length*embedding_dim,数据的原始大小并没有变化 - target sentence进行分词和添加位置信息之后,便输入到Decoder当中,大小为:
target_length*embedding_dim - Decoder中的每一层都要使用Encoder的输入,整体输出大小为:
target_length*embedding_dim - 最后连接一个Linear层,然后其输出大小为:
target_length*vocab_size
以上便是Transformer中的数据流向过程,那接下来我将介绍每一个细节。
输入表示
input sentence 和 target sentence 都是需要进行编码,最终得到一个input_length * embedding_dim向量,那这是如何得到文本的向量表示的呢?
主要分为两个步骤:
- Token Embedding
- Encoding of Positions
原始文本和目标文本的编码过程是一致的。Token Embedding的原理我就不介绍了,与通用的方法一致,Encoding of Positions的原理可用以下公式来表示:
Encoder Layer
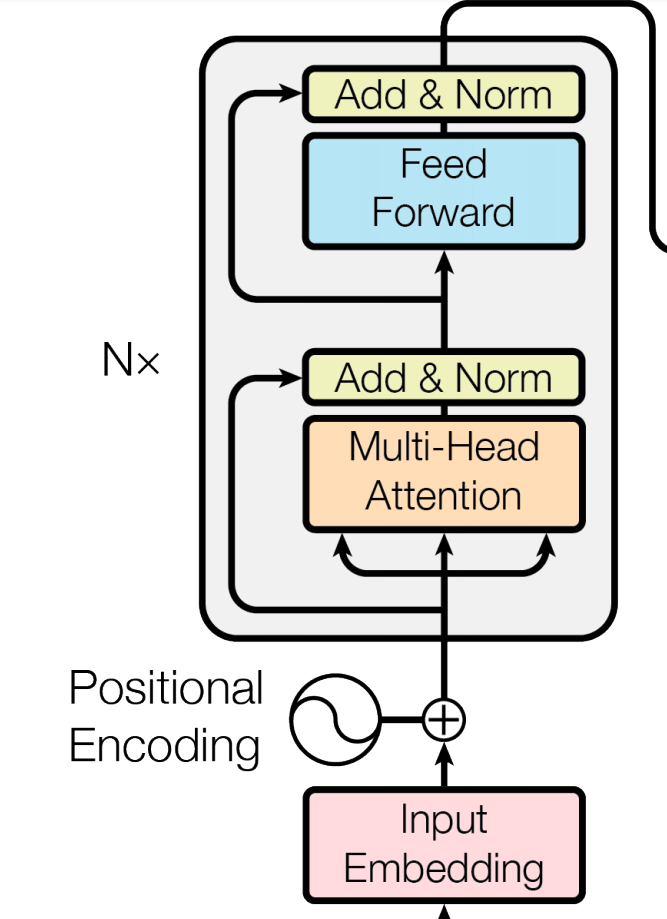
其中N个Layer链式连接,上一个的输出就是下一个的输入(而且输入和输出的维度大小一致),通过层级连接,能够捕捉到不同层次之间的上下文关系,这个过程也可以认为是sentence-level并非word-level的建模。
Multi-Header Layer
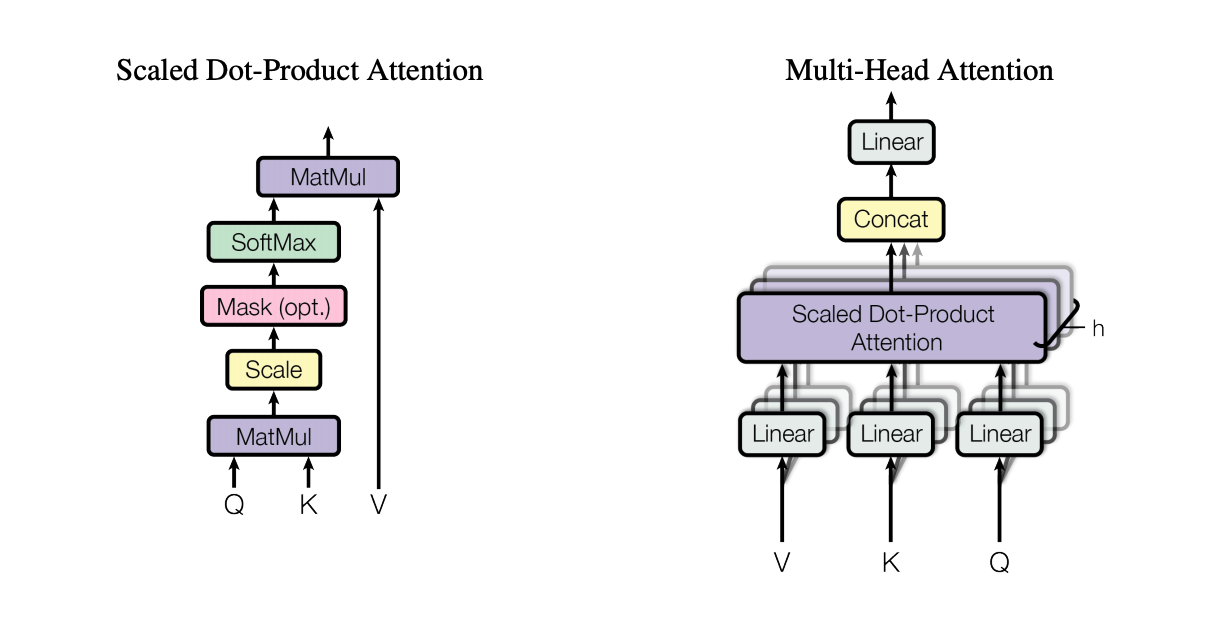
内部有h个Dot-Product Attention连接:多个独立可学习的参数的特征空间,提升某一层的宽度,提取更多的特征空间。
有研究表明,深的网络比宽的网络效果更好。而Bert无论你是宽度还是深度都比较适中,或许这就是理想情况下的结构。
- multi-head:提取特征的数量
- N-Transformer:提取复杂的特征
核心公式如下所示:


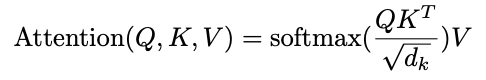
QK^t 的结果大小是:(input_length * input_length)
可以将Attention看作是给sentence中不同token之间建模相似度关系
- QK都是input通过不同的权重矩阵映射而来,最后通过dot-product计算映射的相似性,并最终得到一个token-level上的相似度。
- d_k 是放缩因子,能够减少不同维度大小带来的影响。
[SEP] token
Bert 其实是可以应用于多种下有任务当中,其中有一个应用场景就是需要对两段文本进行编码,比如Question Answer任务当中就需要将两个句子拼接到一起,然后塞入到Bert当中编码。那对两个句子进行语义层面的分割便成为了一个问题。
于是就引入了[SEP]标签:在每一个文本的末尾都添加一个[SEP]标签来分割两端,从而让模型
Dropout, Add & Norm
MultiHead 结构的输出是: (input_length, embedding_dim),接着将会有Dropout、残差网络已经正则化的处理过程,两处的Dropout都是0.1。
SubLayer:FeedForward、Multi-Head。整体公式为:x + Dropout(Sublayer(x))。
接着会有一个token-wise/row-wise级别的正则化来保证该层数据的稳定性,以此来保证参数学习的范围不要太偏。
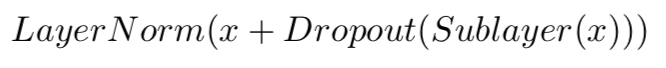
理解MultiHead
整体理解:Token Representation + Token Relationship Representation。
换句话说:保留原始token的语义,理解强相关的词与词之间的关系。
总结
- Bert仅仅是使用了Transformer中的Encoder。
- 由于每一层的输入和输出维度大小一致,故是可以使用链式连接建模。
训练方法
Bert是双向自编码语言模型,训练阶段使用了两种方法:Mask Language Model 以及 Next Sentence Prediction。前者主要是为了学习一个丰富的上下文信息,后者为部分下游任务设计(如QA、NLI等任务),目的是建模句子与句子之间的联系。
一堆问题
Self-Attention is BiDirectional
参考:
- Bert是双向模型,基于Transformer Encoder中的 Bidirectional Self-Attention。
- Self-Attention 可以获取left-tokens 和 right-tokens,所以被称为是bidirectional。
- GPT 是单向模型,基于Transformer Decoder,仅仅是将每一个是token都添加为输入,并生成对应的输出。
- 只能够将left-tokens添加到输入当中,输出预测tokens,故称之为unidirectional。
为什么 [CLS] 能作为整个文本的表示
Bert的输入中,每一个文本开头都会插入一个[CLS]标签,在文本分类的过程中会使用这个位置的标签来作为整个sentence的representation,实践证明效果是非常好的,可是为什么呢?
- 这个要从Self-Attention说起。Self-Attention中的每一个tokne都可以获得整个sentence的tokens表示,也就是全局的含义表示。而[CLS]虽然是在文本的第一个位置,可是依然不影响能够获得全局的编码。
- 选择固定位置的token和指定位置的token表示,其实效果差别挺大的。比如在文本中:
the cat in the hat和i like the cat中的the表示的含义是不一致的,而且位置信息也不一致的,没有办法通过指定的token来表示整个sentence。所以选择一个固定位置的token来作为sentence的表示显得尤为重要。 - [CLS]标签在第一层Transformer中只是一个初始化的token embedding表示,可是在Self-Attention的加持下,在每一层Transformer迭代的时候,都能够添加获不同层面的all token 编码信息,所以在最后一层的时候是有丰富的sentence-level信息编码。
总结
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
衍生模型
RoBERTa
XLNet
AlBERTa
FastBert
权重共享的BERT。
参考链接: